We've been at a series of conferences and events this summer, and at every single one, the same conversation keeps happening. Someone building a product, tool, or feature on top of AI pulls us aside and asks: "Should we use GPT, or Claude, or Gemini? Which model is best?"
For day-to-day use, sure, have a preference. But when you're plugging a model into a feature, almost nobody asking that question is asking the one that actually determines whether the thing works.
The change that didn't get a press release
A year or two ago, the buzzword was prompt engineering. Remember when companies were posting jobs for "Prompt Engineers" and everyone suddenly had a course on it? 😂 The idea was that if you just phrased your request clearly enough, said the magic words in the magic order, you'd unlock dramatically better output. There was a brief golden age of "you're an expert copywriter with twenty years of experience" preambles.
That era is pretty much over. The thing that replaced it has a less catchy name but a lot more substance: context engineering. Both the serious practitioners and the labs themselves have landed on the term.
Here's the difference: the single biggest lever on whether an AI feature is reliable isn't a clever prompt, and it isn't the choice of model. It's context. The full set of information you put in front of the model when you ask it to do something. Get that right and a perfectly ordinary model does excellent work. Get it wrong and the most advanced model on earth produces confident slop.
What context actually means (and why your mental model is too small)
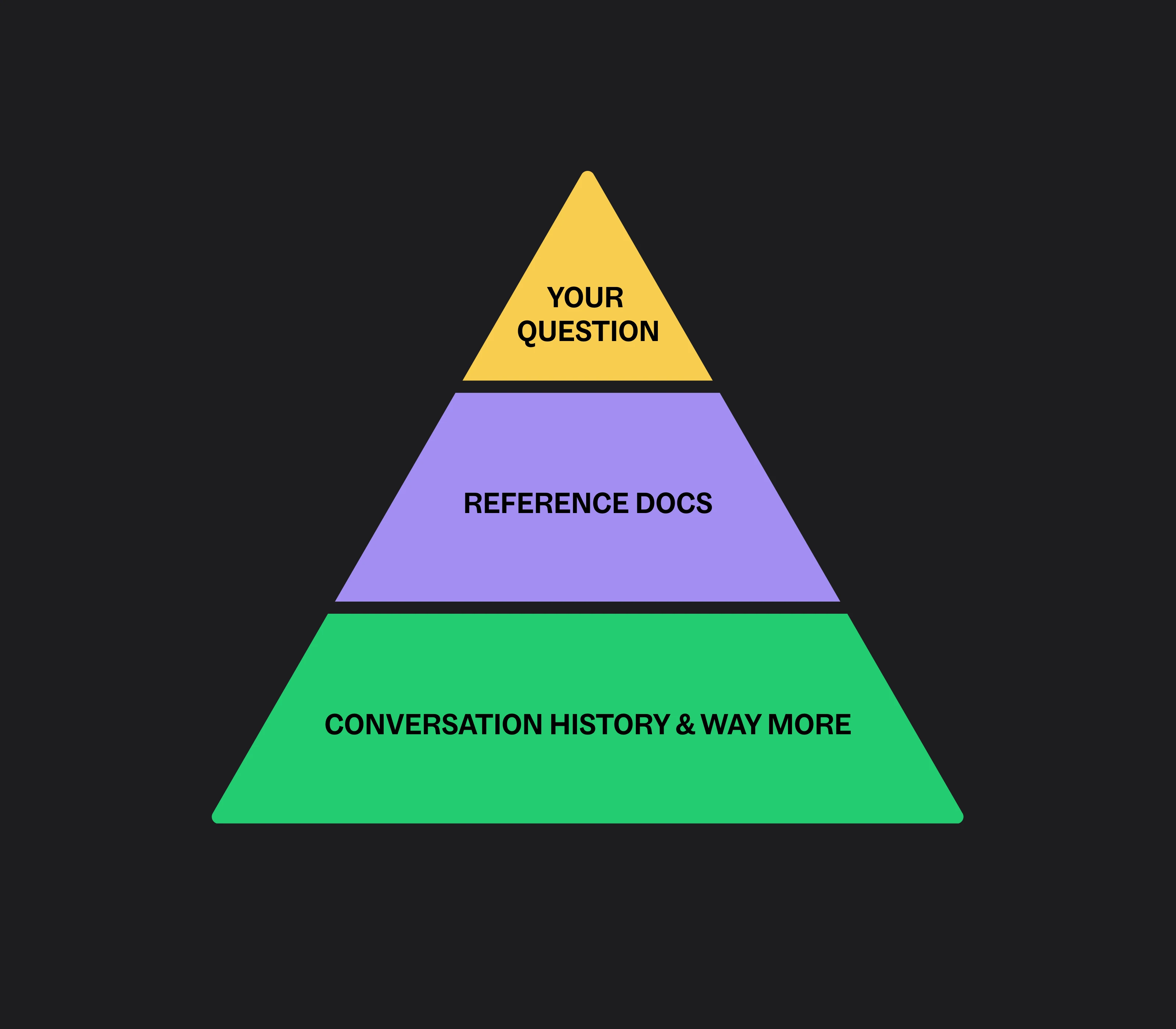
Most people hear "context" and think it means the question they typed. That's only a sliver of it.
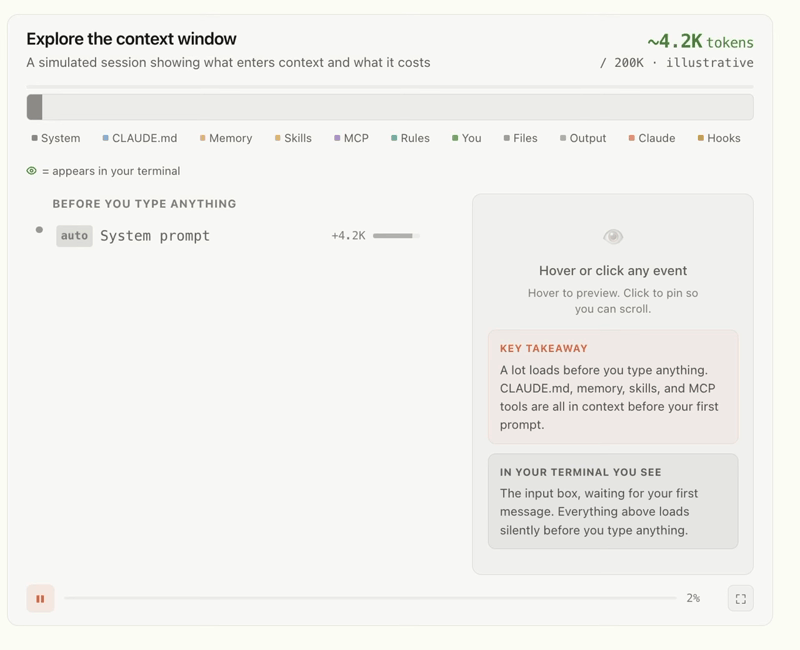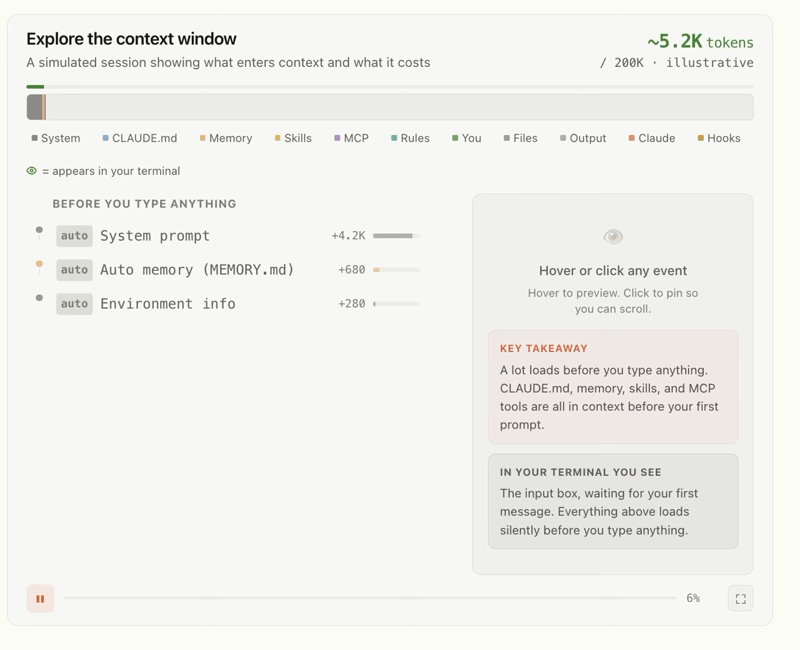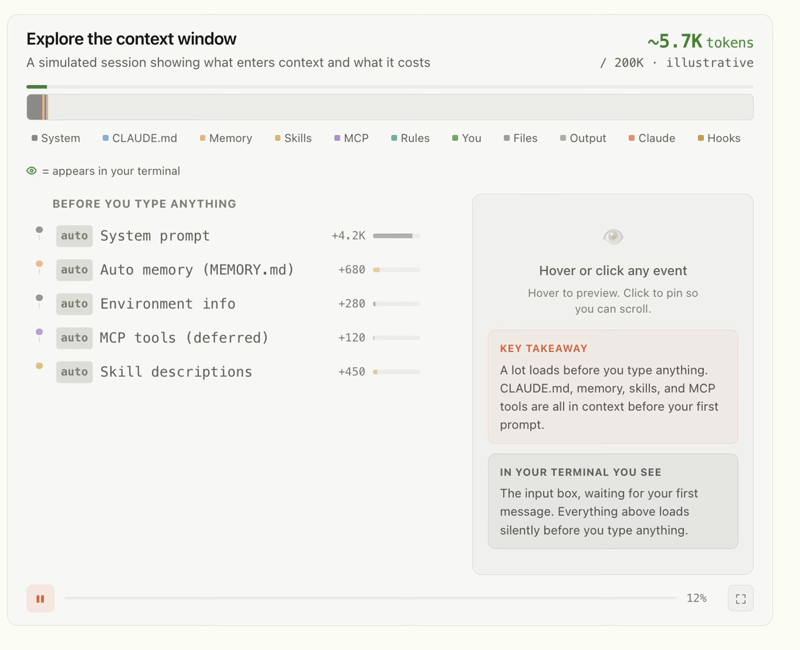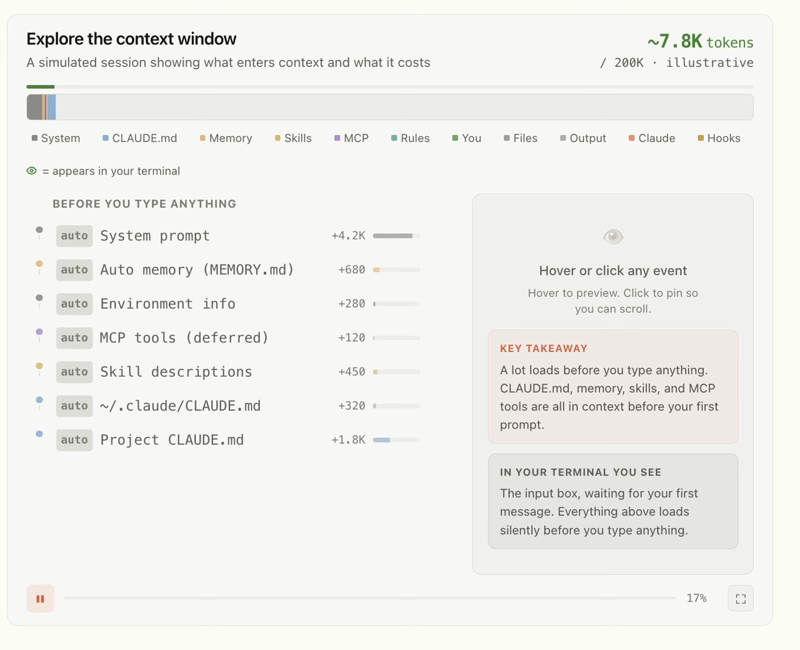
Context is everything the model can see at the moment it answers: the instructions you gave it about how to behave, the examples you showed it of good output, the documents and data you retrieved and handed over, the conversation history, the definitions of any tools it's allowed to use. All of it, together, is the context. Your question is just the last little piece on top.
The analogy we keep reaching for is onboarding a new hire. Imagine you bring in a genuinely brilliant person, top of their field, and on day one you point at a desk and say "go." No explanation of what the company does, no examples of good work, no access to the files, no sense of who to ask. They'll flounder, and you'll conclude you hired wrong.
Now imagine the same person with a structured first week: the context of the role, examples of what good looks like, the documents they need, a clear picture of the goal. Same human being, same talent, completely different output.
The model is the new hire. Context is the onboarding. And almost everyone is blaming the hire for a week they never gave them.
Why the same model behaves so differently
The exact same model, asked the exact same question, will produce wildly different answers depending on the context around it. Give it messy, unstructured data and a vague instruction, and it guesses. Its guesses are generic because generic is the safest bet when you've told it nothing.
Give it clean, relevant information, a clear instruction, and a couple of examples of what good looks like, and the same model suddenly sounds like it actually understands your business.
The model never changes between those two attempts. What changed is what it could see. This is why the model debate is mostly a distraction: the gap between the top models on any given task is real but narrow (and mostly felt in highly specialized situations), while the gap between good context and bad context is enormous.
A mediocre prompt with excellent context beats a brilliant prompt with garbage context every single time. If you remember one sentence from this post, make it that one.
The first thing to check when your AI feature underperforms
When your AI feature is underperforming, resist the reflex to switch models. That's the expensive, satisfying, usually wrong move. It feels like progress because you did a thing, but we'd bet money the quality of the output barely changes.
Instead, check what the model is seeing, and just as important, what it isn't. Walk through the context like you're auditing that new hire's first week:
- Does it have the right information? Are you asking it to know something you never told it?
- Are the instructions clear? Does it know what its job is and how to behave?
- Have you given it examples? Or are you hoping it guesses your taste? (Spoiler: it will guess wrong.)
- Is it drowning in noise? A person buried in the wrong files gets slower, not smarter. Models work the same way.
Nine times out of ten, the fix lives in there. The information was missing, buried, or contradictory. The instruction was so vague the model had no choice but to be generic. You fix the context, and the "bad model" you were about to abandon turns out to be perfectly capable. It was just badly briefed, and a badly briefed genius looks identical to a fool until you brief them properly.
So why does this even matter?
Next time your AI feature disappoints, before you switch providers or rewrite the prompt for the tenth time, go look at the context. Treat the model like a brilliant new hire and ask whether you actually gave it the onboarding to succeed.
Usually you didn't. And that's on you, not the model.
If you've got a colleague stuck in the GPT-versus-Claude debate, convinced the right model will fix everything, send them this. It'll save them from a switch that won't actually solve their problem.

.webp)

















